
Week of May 17
What I did
- Deep Learning coursework. This week’s was difficult, mostly because they segmented the code in a way that was pretty unclear. For example, backpropagation was split into three different functions in three different classes. It was frustrating.
- Read another few chapters of my stats textbook. These were mostly a review of hypothesis testing and associated terms.
- I thought about how I would build a word cloud for my facebook chat data.
What I learned
- I realized that I didn’t understand backpropagation as well as I thought. See what I will do next.
-
Here are some important definitions to remember:
- Null Hypothesis: \(H_0\), the original hypothesis you’re testing.
-
One- vs. Two-tailed Tests: If the null hypothesis has ≠ vs. > or <.
- Significance Level: α, the area of the normal curve outside your confidence interval. Confidence interval is 1 - α. Significance level is also the probability of having a type I error.
- Type I Error: α. False positive. This is when you reject a null hypothesis that is actually true.
- Type II Error: β. False negative. This is when you do not reject a null hypothesis that is actually false
- Test Power: 1 - β. Ability of a test to detect false null hypothesis. On the internal of [0,1], 0 means your H-test is worthless, 1 means it’s really good.
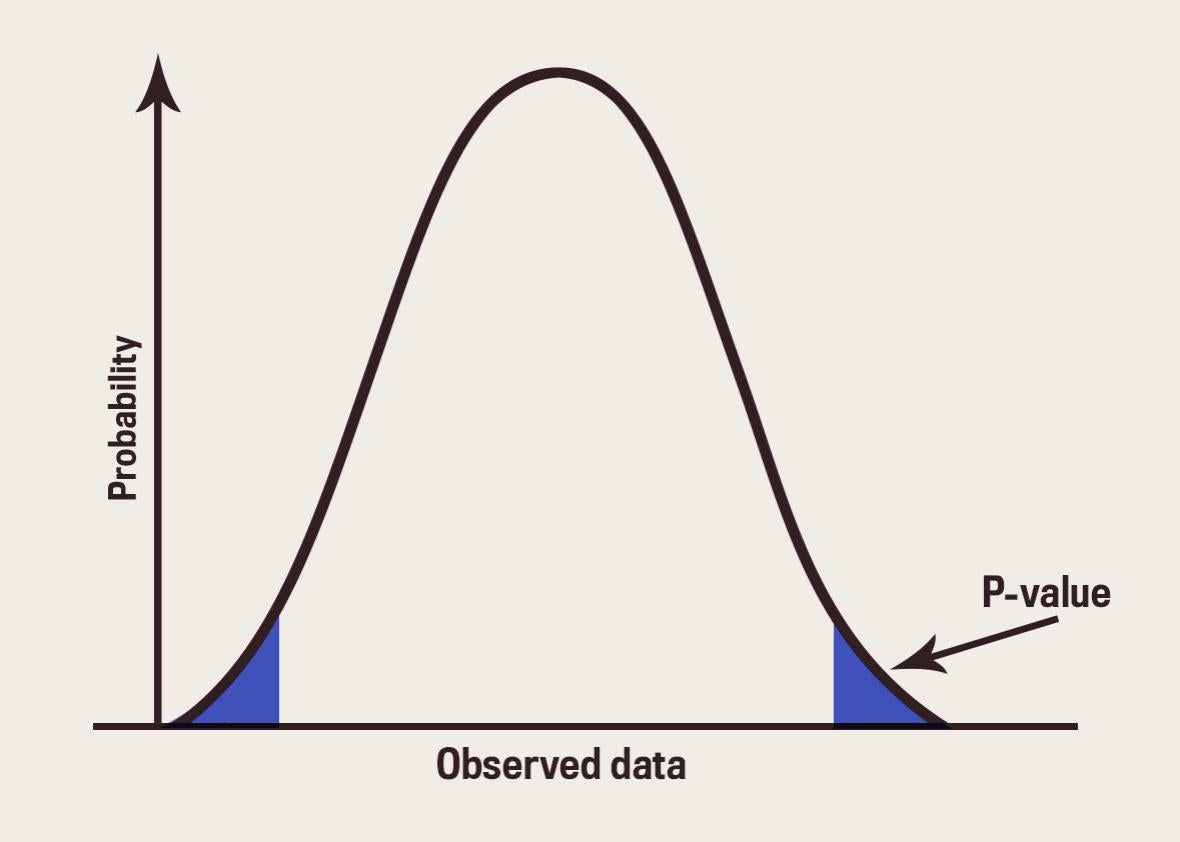
- One sample z-test vs. p-value: For a z-test, you compute the critical values \(Z_\alpha\) or \(Z_{\alpha/2} (one-tail vs two-tailed\) for significance level of α. Then reject the hypothesis if the z-score is outside of this range. For a p-value test, you calculate the probability of observing a value as or more extreme than that observed. If p-value is too small, reject the null hypothesis.
What I will do next
- I think I would benefit greatly from writing an article about how backpropagation works. It would likely have to be quite lengthy though, so I might create a separate post for it. It’s also quite difficult to explain without figures, so it would take me some time to do it well.
- If I have time next week, I’d like to create a word cloud from my chat data. It shouldn’t take more than a few hours. Most the code is already written. It’s just a matter of properly preprocessing. TF-IDF wouldn’t really make sense unless I fed the program my entire corpus of fb messages. Instead, I think I’ll just need to filter out the most common, useless words by importing a package like STOPWORDS.