
Week of November 29th
Homo and heteroskedasticity. When to use NumPy vs. Pandas.
What I did
- I learned some statistics terms and practiced a bit with dataframes.
What I learned
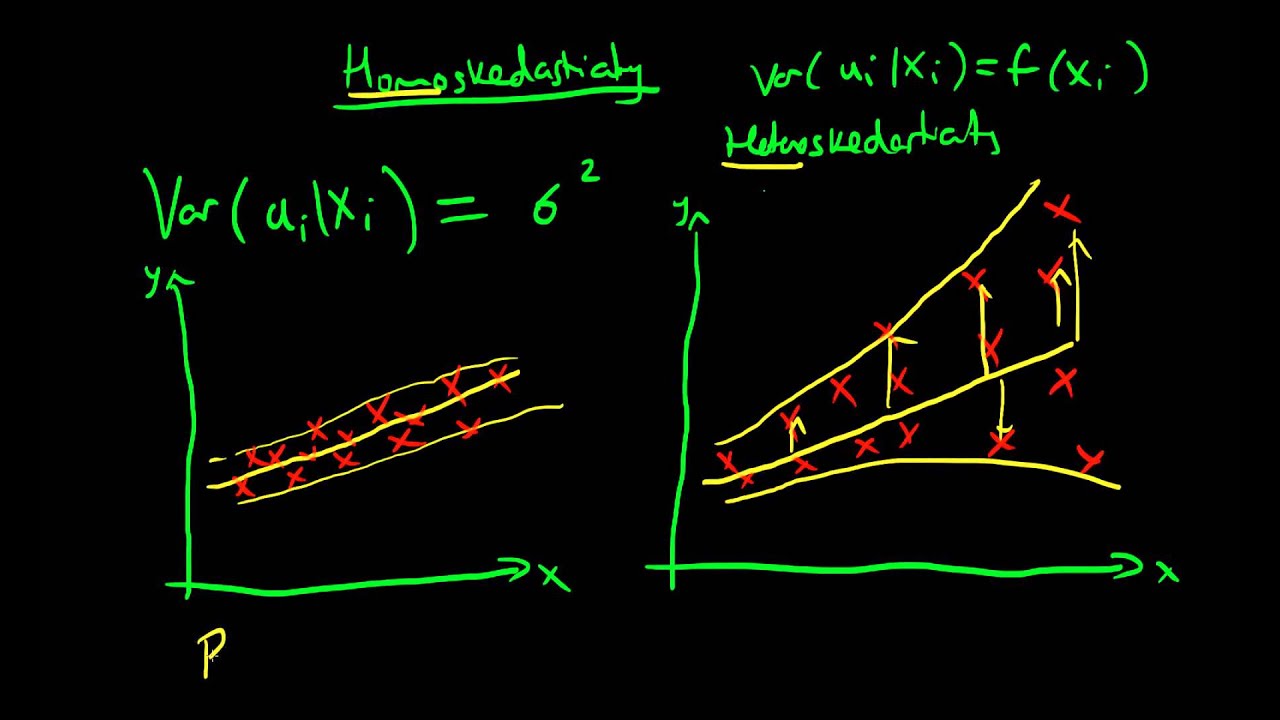
- Homoskedasticity
- Interested in the behavior of our errors/residuals. If the variance of our errors given independent variable x is constant, we have homoskedasticity.
\[var(a_i \vert x_i) = constant\]
-
Heteroskedasticity
- When the errors are not constant, and the size of the errors is a function of your independent variable.
\[var(a_i \vert x_i) = f(x_i)\]
- Commonly, this might mean that your model gets worse at predicting as the x values increase. This could indicate a few things. You might not be taking into account enough/all the information needed for OLS to work well. Another least squares algorithm could perform better (be homoskedastic). You could also try a different type of regression or a more complicated ML model.
-
Data leakage is when information from outside the training dataset is used to create the model. good quiz question. Do train-test-validation split first.
-
Pandas Series vs. Numpy Arrays
- A good rule of thumb is to choose the simplest data structure that satisfies what you need. List and dictionaries are the simplest, then use Pandas when you have more dimensions or are making lots of mathematical operations, and finally use Numpy when you have many data structures or sources or are importing the data from somewhere else.
What I will do next
- PANDAS practice!