
Week of July 26th
What I did
- I worked a little on my chatbot. Preprocessing works. Only need to decide how to deal with emojis next.
- I started reviewing/studying for my deep learning course.
What I learned
Review for Test
-
We need activation functions for neural networks and more complicated machine learning models in order to introduce non-linearity. If you don’t have an activation function, or you have a linear activation function, you end up just doing affine transformations. This means there’s no point in having more complicated layers, and you might as well just have one layer with different weights and biases.
-
To calculate the number of parameters in a CNN, use the formula:
For example, consider the output size of a CNN with an input size of 32x32x32 when 8 filters of size 6x6 are applied to it with a padding of 1 and stride size of 2.
- W is the input volume - in this case 32
- K is the Kernel size - in this case 6
- P is the padding - in this case 1, since not stated
- S is the stride - which you have not provided.
Output_Shape = (32-6+2(1))/2+1 = 15
Output_Shape = 15 x 15 x 40
Here’s an example image (it’s AlexNET) to see some concrete examples of this calculation:
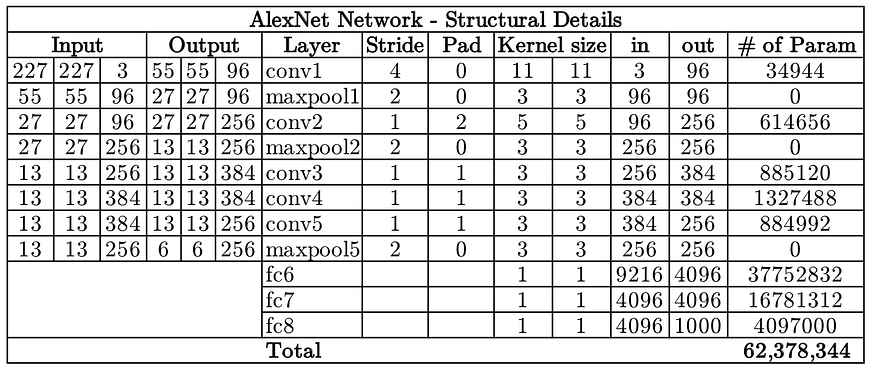
- Note, zero padding is helpful for the first few layers in order to conserve spacial dimensionality (input volume = output volume).
What I will do next
- Continue reviewing for my Deep Learning exam. Maybe I can find exams for similar courses online to practice.